-
Valid criticism of the official Google Blog's headlines, and good advice for any weblog author. Headlines are insanely important in the age of aggregation.
-
free VPN application [thanks, mathowie]
-
now you can talk like Mr. Burns! [via kottke]
weblogs
-
Yet another site you can ping when you update your blog. This one's for Google's Blog Search. Ping!
-
Nice tutorial that shows how you can saturate the colors in a photo by switching to Lab Color mode and messing with the channels. [via nelson]
-
search for code in specific languages (except VB?) from across the web.
-
lectures from UC Berkeley classes online. [via Searchblog]
-
looks better than parallels for running a single Windows app on OSX. (though I can't get this beta version to run.)
-
Marc Hedlund just started a blog for his personal finance startup
A Slice of the Blogosphere
The Oregon weblogs site I run (ORblogs) is watching a tiny slice of the blogosphere. The site is currently tracking 1,051 active weblogs, and that number is made up of weblogs by people who choose to participate at the site. (And there are currently 48.3 million weblogs, according to Technorati.) ORblogs tracks a bunch of metadata from these 1,000+ participating blogs, with most of the data exposed in various ways across the site. However there are a few bits of data that you don't see on the site, and I think it's interesting to run some numbers and share them once in a while.
One bit of data collected from RSS feeds is the generator. If you look at the source XML of most RSS or Atom feeds, you'll often see a
Without further explanation, here's weblog tool usage across Oregon weblogs flowing through ORblogs:
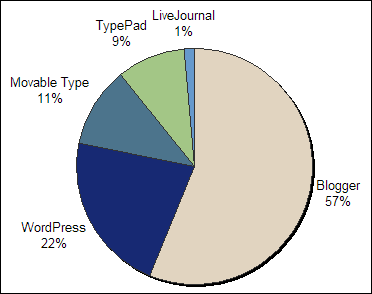
But wait! That doesn't add up to 1,051. True, of the total active weblogs, 70 don't have a feed associated with their listing. (Typically because their weblog HTML is missing an auto-discovery tag, or the tag contains a bad URL.) And of the rest that do have a feed associated with their listing, 173 feeds didn't have a generator listed. The rest were generators that numbered four or fewer such as Microsoft Spaces, and PMachine.
"What about FeedBurner?", you cry. ORblogs is tracking that usage too, and luckily FeedBurner passes the original generator information through in its feeds. Of these blogs, 55 were using FeedBurner.
Another interesting bit of data typically stored in these generator tags is a version number for the software. Here's how some of the version numbers break down (when a version number was available):
Blogger (who knew they had versions?):
And that's what's happening with a slice of the Oregon blogosphere as of July 14th, 2006.
Update: And for fun, here's a similar survey I ran using the HTML generator tag in 2004 back when ORblogs was tracking just 309 weblogs: ORblogs Forum: Weblog Tool Survey. Blogger and Movable Type were tied back then.
One bit of data collected from RSS feeds is the generator. If you look at the source XML of most RSS or Atom feeds, you'll often see a
generator or admin:generatorAgent tag. And because weblog authors usually don't touch their feed templates—if they have access to their feed design at all—this tag is a fairly good way to see which weblog tool was used to generate any given weblog.
Without further explanation, here's weblog tool usage across Oregon weblogs flowing through ORblogs:
- Blogger: 431
- WordPress: 167
- Movable Type: 87
- TypePad: 72
- LiveJournal: 11
But wait! That doesn't add up to 1,051. True, of the total active weblogs, 70 don't have a feed associated with their listing. (Typically because their weblog HTML is missing an auto-discovery tag, or the tag contains a bad URL.) And of the rest that do have a feed associated with their listing, 173 feeds didn't have a generator listed. The rest were generators that numbered four or fewer such as Microsoft Spaces, and PMachine.
"What about FeedBurner?", you cry. ORblogs is tracking that usage too, and luckily FeedBurner passes the original generator information through in its feeds. Of these blogs, 55 were using FeedBurner.
Another interesting bit of data typically stored in these generator tags is a version number for the software. Here's how some of the version numbers break down (when a version number was available):
Blogger (who knew they had versions?):
- Blogger 6.72: 344
- Blogger 5.15: 76
- WordPress 2.0.3: 33
- WordPress 2.0.2: 28
- WordPress 1.5.2: 22
- WordPress 2.0.1: 18
- WordPress 1.5.1.3: 11
- WordPress 2: 9
- WordPress 1.5: 8
- WordPress MU: 7
- Movable Type 3.2: 52
- Movable Type 3.121: 5
- Movable Type 3.17: 5
- Movable Type 2.63: 4
- Movable Type 2.64: 4
- Movable Type 2.661: 4
- Movable Type 3.15: 4
And that's what's happening with a slice of the Oregon blogosphere as of July 14th, 2006.
Update: And for fun, here's a similar survey I ran using the HTML generator tag in 2004 back when ORblogs was tracking just 309 weblogs: ORblogs Forum: Weblog Tool Survey. Blogger and Movable Type were tied back then.
eJournal USA mentions onfocus
The US Department of State mentioned this site in their monthly eJournal, an issue called Media Emerging. It was in an articled about online photo journals, and you can see the article here: Online Albums. Click Enter Album to see all of the photoblogs mentioned. They also have an article about blogs: Bloggers Breaking Ground in Communication. It's great to be mentioned as a photoblogger even though I don't necessarily think of myself in that category anymore. But it's a good reminder that I should keep posting photos. They contacted me about the article a week or two ago and it was strange to see an email in my inbox with the subject, request from U.S. Dept of State.
Link Blogs
The only reason I'm still not caught up on reading after my vacation: link blogs. Email, done. Weblogs, done. Link blogs—over 1,000 links still unread. How do I keep up with this stuff on a daily basis?
Guest Post at Yahoo! Search blog
I'm a guest blogger today over at the Yahoo! Search blog talking about (what else?) Yahoo! Hacks. The Good Kind....
Wired Gear Factor
If you want to subscribe to an Engadget/Gizmodo style weblog about consumer electronics that doesn't have advertising in its RSS feed, check out Gear Factor by Wired (RSS). Since these types of blogs are essentially a type of advertising anyway, I don't understand the need for extra ads in the feed.
Power of defaults
Interesting article in the Economist this week about Google, Yahoo!, and MSN's interest in AOL: The battle of the portals. This last bit was surprising:
Ultimately, it all comes down to the three suitors' estimates of what Mr Varian calls "the power of the default". Default users are "the great unwashed", says Mr Varian. They are the ones who, for instance, use MSN because it comes pre-installed in Internet Explorer, the web browser that itself comes pre-installed on new computers...Default users are less demanding, older but nonetheless rich enough to target with small hyperlinked text advertisements. For the dealmakers, it all comes down to figuring out how much these naifs, collectively, are worth.I think the power of the default is diminishing, but I have no proof to back it up. Firefox, blogging, flickring, and even the rise of Google all indicate people are willing to go beyond what's placed directly in front of them. The teenagers and geeks the article mentions who change defaults don't account for the millions who are changing browsers and publishing online. I'm sure defaults are still an important force, but I think their value is waning.
How can I cash out?
Re: AOL buying Weblogs, Inc.
Even though my blog isn't worth millions, its sentimental value is through the roof. I'm going to keep it.

My blog is worth $71,696.58.
How much is your blog worth?
![]()
Even though my blog isn't worth millions, its sentimental value is through the roof. I'm going to keep it.
Goodbye Weblog Bookwatch
On April 14th, 2002 I launched the Weblog Bookwatch—a look at the most frequently mentioned books across the blogosphere. (original post) Since then, the bookwatch has dutifully scanned the blogosphere day in and day out, noting book ISBNs (and Amazon CD ASINs) and the blogs where they were spotted.
In 2002 there were a fairly manageable number of blogs to scan. Between April and December 2002 there were 36,790 unique citations across 5,207 unique weblogs. Just to give you a sense of the size today, the Bookwatch scanned 47,512 weblogs today between the hours of 12am and 6am. I have a database with over two million citations in it, and it's growing exponentially.
I got an email from my ISP today informing me that I was over my bandwidth limit. I thought that was odd, did I get Slashdotted and not know it? My logs didn't indicate any spikes. Nope, the problem was traffic from my machine. In other words, scanning close to 50,000 weblogs every six hours tends to use some bandwidth. That got me thinking about whether or not I can afford to keep the Bookwatch running.
But what about all that sweet Amazon cash? It's true that the book links on the Weblog Bookwatch are an associate link to Amazon—and I get a cut when people buy books through them. But it has never been a big money maker. In Q2 of 2005 I made $118.67, which isn't even close to covering a month of hosting with my current setup.
I've enjoyed clicking through the sites to read what people are saying about books that show up on the page. But the Bookwatch can't keep up with the entire blogosphere anymore, and there are a couple of great services with more resources that track book mentions across weblogs (and much more!): All Consuming and Technorati Books.
I learned a lot about weblogs and gathering data while running and tuning the Bookwatch, and now it's teaching me about when an experiment should end. So as of today, the
In 2002 there were a fairly manageable number of blogs to scan. Between April and December 2002 there were 36,790 unique citations across 5,207 unique weblogs. Just to give you a sense of the size today, the Bookwatch scanned 47,512 weblogs today between the hours of 12am and 6am. I have a database with over two million citations in it, and it's growing exponentially.
I got an email from my ISP today informing me that I was over my bandwidth limit. I thought that was odd, did I get Slashdotted and not know it? My logs didn't indicate any spikes. Nope, the problem was traffic from my machine. In other words, scanning close to 50,000 weblogs every six hours tends to use some bandwidth. That got me thinking about whether or not I can afford to keep the Bookwatch running.
But what about all that sweet Amazon cash? It's true that the book links on the Weblog Bookwatch are an associate link to Amazon—and I get a cut when people buy books through them. But it has never been a big money maker. In Q2 of 2005 I made $118.67, which isn't even close to covering a month of hosting with my current setup.
I've enjoyed clicking through the sites to read what people are saying about books that show up on the page. But the Bookwatch can't keep up with the entire blogosphere anymore, and there are a couple of great services with more resources that track book mentions across weblogs (and much more!): All Consuming and Technorati Books.
I learned a lot about weblogs and gathering data while running and tuning the Bookwatch, and now it's teaching me about when an experiment should end. So as of today, the
obidos-bot has crawled its last site. It's been a fun app, but it's time to say goodbye to Weblog Bookwatch. Thanks (again) to weblogs.com, Blogger, and Amazon for publishing data in an easy-to-use format. Ads in RSS
My new policy: I immediately unsubscribe from any XML feed with ads in it. Unless it's a feed about ads, then I might consider it. But then the post excerpts wouldn't necessarily be ads themsleves, would they? That might be unreasonable, but enough is enough. Buy nike.