Add Camera Images to Flickr
When I'm browsing photos on Flickr, I use the More Properties link quite a bit. That's the link that takes you to the Exif data associated with a photo if it's available. Embedded Exif data is how Flickr knows what type of camera took a particular photo, what the shutter speed was, aperture setting, and a bunch of other technical details about the state of the camera at the time the photo was taken. The more properties link is to the right of a photo on Flickr, and looks like this when it's there:
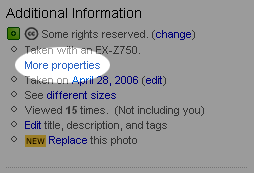
The first thing I look at on the More Properties page is the camera model. But unless I know a particular camera model number already, it doesn't tell me much. "Ahh yes, the EX-Z750," I tell myself. Of course I have no idea what that model number means. So if I really want to know what type of camera the photographer used, I have to copy the model number, go to Amazon or Google, paste it in, and sort through the results. I knew there had to be a better way.
So I wrote a (relatively) quick Greasemonkey script that does the work of looking up the camera model for me. It even inserts a picture of that particular model on the Flickr "More properties" page. Here's what it looks like in action.
More properties page before:
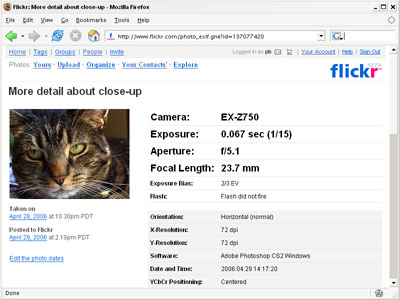
More properties page after:
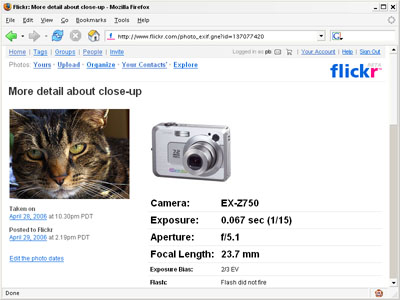
And you can click the camera image to view more info about the camera at Amazon. Bonus for me: if you buy the camera through that link, I'll get a little kickback through Amazon's Associates Program.
Here's how it works. The script grabs the camera model from the Flickr page, contacts the Amazon API looking for that model in the Camera & Photo category, then grabs the image of the first result. Then the script inserts the image and a link to the product page into the page at Flickr.
It's not perfect. Sometimes Amazon doesn't carry that particular camera but has accessories that include a description with the model number. So you'll see a flash or remote shutter release instead of a camera. And sometimes the first result from Amazon isn't the correct model number—especially with older cameras. I'll keep tinkering with it to see if I can get more accurate results from Amazon.
If there's no match at all on Amazon, the script makes the model number a link to Google search results for that phrase.
The script just gives me a quick look at the type of camera that took the photo. I've been surprised to see cameras that look like video cameras taking nice still photos. Anyway, it was fun to put together and I learned a bit more about JavaScript.
If you already have Firefox with Greasemonkey installed, you can install this script for youself here: Flickr Camera Images
Thanks to the author of Monkey Match for a solid Amazon E4X parsing example, and of course Dive Into Greasemonkey. For more fun hacking around with with these applications check out Flickr Hacks and Amazon Hacks. (disclaimer: as you probably know I worked on both of these books.)
The first thing I look at on the More Properties page is the camera model. But unless I know a particular camera model number already, it doesn't tell me much. "Ahh yes, the EX-Z750," I tell myself. Of course I have no idea what that model number means. So if I really want to know what type of camera the photographer used, I have to copy the model number, go to Amazon or Google, paste it in, and sort through the results. I knew there had to be a better way.
So I wrote a (relatively) quick Greasemonkey script that does the work of looking up the camera model for me. It even inserts a picture of that particular model on the Flickr "More properties" page. Here's what it looks like in action.
More properties page before:
More properties page after:
And you can click the camera image to view more info about the camera at Amazon. Bonus for me: if you buy the camera through that link, I'll get a little kickback through Amazon's Associates Program.
Here's how it works. The script grabs the camera model from the Flickr page, contacts the Amazon API looking for that model in the Camera & Photo category, then grabs the image of the first result. Then the script inserts the image and a link to the product page into the page at Flickr.
It's not perfect. Sometimes Amazon doesn't carry that particular camera but has accessories that include a description with the model number. So you'll see a flash or remote shutter release instead of a camera. And sometimes the first result from Amazon isn't the correct model number—especially with older cameras. I'll keep tinkering with it to see if I can get more accurate results from Amazon.
If there's no match at all on Amazon, the script makes the model number a link to Google search results for that phrase.
The script just gives me a quick look at the type of camera that took the photo. I've been surprised to see cameras that look like video cameras taking nice still photos. Anyway, it was fun to put together and I learned a bit more about JavaScript.
If you already have Firefox with Greasemonkey installed, you can install this script for youself here: Flickr Camera Images
Thanks to the author of Monkey Match for a solid Amazon E4X parsing example, and of course Dive Into Greasemonkey. For more fun hacking around with with these applications check out Flickr Hacks and Amazon Hacks. (disclaimer: as you probably know I worked on both of these books.)